We saw in the previous part “Getting started with Apache Spark (Part 1)” a general overview of Spark where I presented some Spark APIs and illustrate them with examples . Recently I worked on Spark Streaming so it’s the occasion for me to introduce some concepts. This part will be about real time processing data with Spark Streaming and Kafka.
I will start by explaining what is Spark Streaming and Kafka, then I will present some APIs, and finally I will speak about stateful applications and illustrating them with an example.
Spark Streaming
Spark Streaming is an extension of the Spark API that allows fast, scalable and secure processing of data from various sources such as Kafka, HDFS, Etc. Then, after processing, the data will be sent to file systems, dashboards and databases.
Spark Streaming uses micro-batches where it receives the data and divides it into several mini-batch RDDs which are then processed by the Spark Engine to produce the batch results stream.


Why Apache Kafka ?
Kafka is an open-source distributed message broker that was developed by LinkedIn in 2009. Since 2012, it has been maintained by the Apache Foundation.
With its fault tolerance, high availability and low resource usage, Kafka has the arguments to become a standard in data processing pipelines. It is also suitable for batch processing as streams.
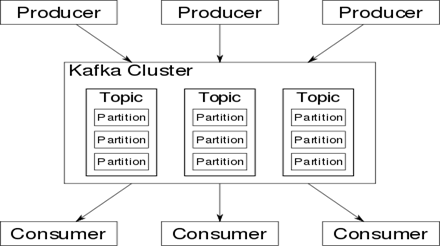
Kafka runs as a cluster on one or more servers that can span multiple data centers and the cluster stores streams of records in categories called topics also and each record consists of a key, a value and a timestamp.
Kafka has a producer API that allows an application to send data streams to the Kafka cluster and a consumer API that allows an application to read data streams from the cluster produced to them.

Install Kafka on linux
- Download the .tgz file on this link
- Execute the following command lines
tar -xzf kafka_2.12–2.5.0.tgz
cd kafka_2.12–2.5.0
Start the Zookeeper server and Kafka server
In order to start kafka services we should start by launching Zookeeper server using the command line below:
bin/zookeeper-server-start.sh config/zookeeper.properties
Then starting kafka server:
bin/kafka-server-start.sh config/server.properties
Kafka Topic:
It’s used to store data in Kafka. Each topic corresponds to a category of data. The systems that publish data in Kafka topics are Producers. The systems that read data from them are Consumers.
To create a topic we use this command line:
bin/kafka-topics.sh — create — bootstrap-server localhost:9092 — replication-factor 1 — partitions 1 — topic < nameTopic >
ps : You must be root to have the ability to execute these command lines.
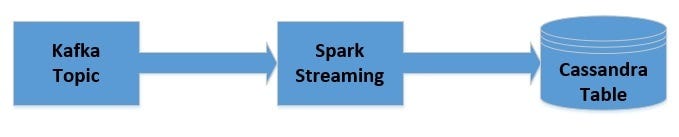
Spark Streaming with Kafka
Kafka acts as a central hub for real-time data streams and is processed using complex algorithms in Spark Streaming. Once the data has been treated, Spark Streaming can publish the results on different Kafka topic or store them in HDFS, databases or dashboards.

Kafka Spark API
1. SparkConf API
It represents a configuration for a Spark application. It is used to define the various Spark parameters as key-value pairs. here are some methods:
a. setAppName (String name): allows you to associate a name to the application.
b. setIfMissing (String key, String value): allows you to configure a parameter if you haven’t already done so.
c. set (String key, String value): allows you to define the configuration variable.


2. StreamingContext API
That is the entry point for Spark Streaming functionality. It gives us the possibility to create DStreams from different input sources using its methods.
We have various ways to create it either by providing a main Spark URL and application’s name, or with a SparkConf configuration, or from an existing SparkContext.

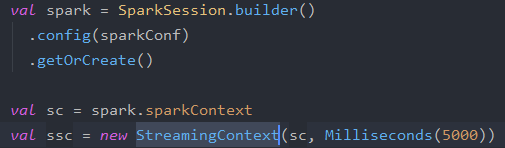
Once it is created and after the DStream transformation, we start the stream calculation with context.start() and stop it with context.stop() we have also context.awaitTermination() which allows the present thread to wait for the end of the context which will be triggered by stop() or by an exception.
3. KafkaUtils API
The KafkaUtils API allows us to connect the kafka cluster to Spark Streaming. In order to create an input stream which retrieves messages from kafka brokers, we use the createDirectStream, in its parameters we should define StreamingContext, some configurations, and also a topic.

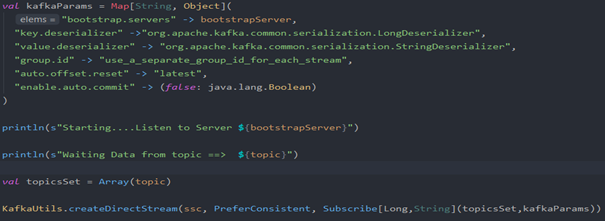
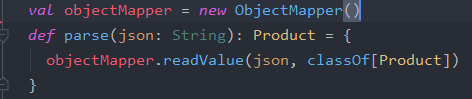
So here we get this consumer records feed, which are in the input field. Once we have this inputStream which is a pair of <key=long, value=String>, I transform it into a DStream to manipulate objects , for this purpose I define a method that convert the records into objects.



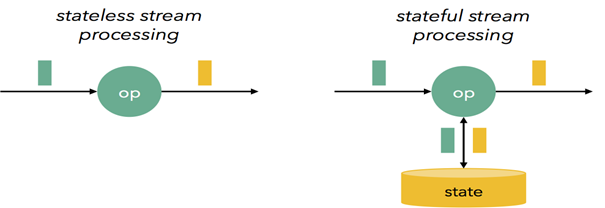
Stateless and Stateful transformations
In stateless processing, each micro-batch of data is processed independently of the other ones, so it does not keep the state.
Whereas, In stateful transformation, the treatment of each data micro-batch depends on the previous result. This means that we have to check the previous state of the RDD in order to update the new one.

In Apache Spark 1.6, there was a support for stateful stream processing using the new API mapWithState that is greatly improved. This API has built-in support for common modes that previously required manual coding and optimization (eg, session timeout) when using updateStateByKey. As a result, mapWithState can provide up to 10 times higher performance than updateStateByKey.
In the example below, In order to manipulate stateful applications I will use the mapWithState function
Example of stateful transformations
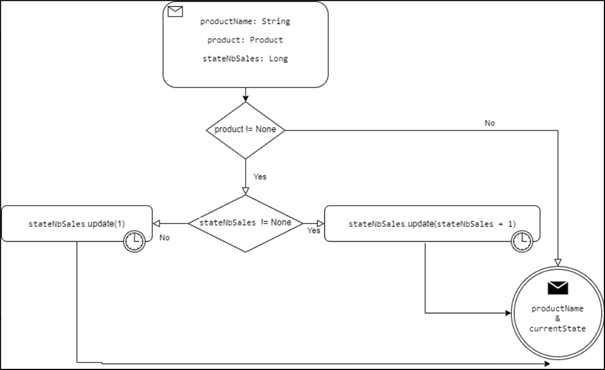
Let’s assume that there is an application that sends events to a kafka topic. These events are about products sale, so we receive them every time someone buys a given product. This data contains information about the products (IdProduct, ProductName, price…) . The purpose of this example is to get the number of sales for each product.
For this purpose, we apply a processing with state, because we have to update the number of sales that we get from previous state for each product that we receive.
First, we use the product name as a key to differentiate the products. Then each time we receive a product we increment the state which is the number of times that the product has been sold.
Obviously there are some cases that need to be managed which are :
First, when we receive a null value, in this case I keep the state as it was before.
Second, when we receive a product for the first time, of course the number of sales is zero(0)! so the state is by default equal to None I’ll initialize it to one(1)

You can find the example source code in my github

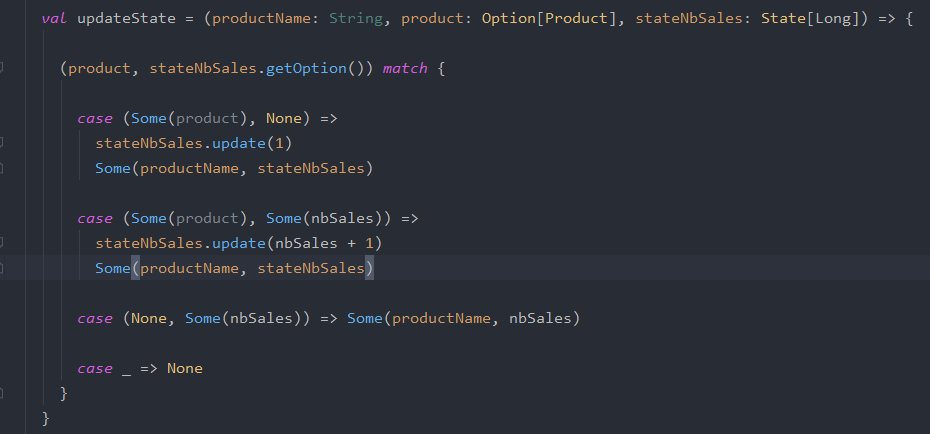
Here, as I mentioned it before I used the mapWithState function, it takes three parameters which are:
key that can be of any type used to differentiate between data.
new value (wrapped as an option) that represents the new incoming value.
state (in the object State) which allows to save the state of the data.
and we have to pass the stateful function to the method of StateSpec.function
function: it allows us to create a StateSpec which is an abstract class representing all the specifications of the mapWithState operation on a DStream pair.
mapWithState provides a native support for session timeouts, where a session must be closed if it hasn’t received new data for some time (e.g. the user has left the session without explicitly logging out). mapWithState timeouts can be directly defined as :


Conclusion :
In this part we have seen real time processing data with Spark Streaming and Kafka, in the next part I will introduce some Spark Structured Streaming concepts.